Video Generation with Open Source Models

Social media has recently been flooded with impressive AI videos made with closed source tools like Sora, Runway, or Kling. In this experiment, I wanted to investigate how far you can get by using only open source AI models.
What is the relevance of open source AI models? First, as Yann LeCun and others argue, there are implications on the highest level; AI is becoming an absolute key technology of our times; it can’t be good for humanity if this power is in the hand of small group of people leading companies in Silicon Valley and Beijing. Second, there is a technical dimension to it. As we saw with Linux vs. Windows: Open Source leads to technical superiority in the long run. Applied to AI, we could observe that it did not take long for open text-to-image models to overtake closed ones (e.g. Stable Diffusion vs. Midjourney).
In the following, I describe details of my experiment, which took 10 hours from concept to final cut. You can also skip directly to the end to see the final result.
Automatic Pipeline
As first step, I set up an automatic pipeline to create videos from images. As input images, I used some beautiful nature photographs (links to all used resources at the bottom of this page). Then, I adapted an awesome ComfyUI workflow to run in my environment (A100 with 80GB VRAM). Final computation speed was just below 2 minutes from an image to a video clip consisting of 49 frames (720x480 pixels). One important aspect of this workflow is that while it includes some text-to-image models, it does not require me to enter text prompts in order to get images; I much prefer a completely visual pipeline.
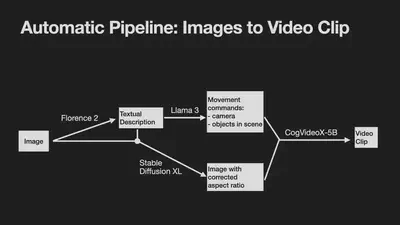
Based on 25 input images, I generated 96 clips in 3 hours, taking just below 2 minutes per clip.
Manual Postprocessing
Out of the 96 generated clips, about half were sufficiently good. I then picked the 23 I liked best and performed spatio-temporal upscaling in Topaz AI to 1920p resolution at 30 fps. Finally, I quickly arranged the clips in iMovie, together with an audio track from Sir Attenborough.
Final Result & Conclusions
The final result is clearly not as good as what can be done with closed source tools (e.g. a recent favorite of mine: La Baie Area). However, it confirmed my opinion about the trajectory of open source video generation models (I have been testing them all…): they will overtake closed sourced ones sooner than expected!
I also learned more about the limitations of CogVideoX: I did a similar experiment with humans in the input images, but they did not work out well. While camera trajectories and actions in the background worked very well, consistency of humans was lacking.
Credits
- Audio: David Attenborough - For All Nature (https://www.youtube.com/watch?v=-a_dMFnib-s)
- Wildlife photographs: https://www.smithsonianmag.com/smart-news/see-25-breathtaking-images-from-the-wildlife-photographer-of-the-year-contest-180983516/
- ComfyUI Workflow: https://github.com/henrique-galimberti/i2v-workflow/blob/main/CogVideoX-I2V-workflow_v2.json
- Models:
- Florence-2-large
- Lexi-Llama-3-8B-Uncensored_Q4_K_M.gguf
- CogVideoX-5b
- Outpainting: RealVisXL V3.0 Inpainting
Christian Sandor
Professor
Interested in Augmented Reality, Artificial Intelligence, and Human Perception